
Nvidia Still Dominates AI Training, but Cerebras Is Changing the Inference Discussion

What’s in This Article
Introduction
Chart 1: Estimated AI Accelerator Market Share by Workload (2026E)
Inference Is Becoming a Different Market Than Training
Table 1: AI Training vs AI Inference Architectural Priorities
Why Cerebras Matters Beyond Its IPO
Table 2: AI Inference Competitive Landscape
Hyperscalers Are Increasingly Optimizing Around Economics
Table 3: Why Hyperscalers Are Developing Their Own AI ASICs
Memory Architecture Is Becoming Increasingly Important
Table 4: AI Memory Requirements – GPU vs ASIC vs Wafer-Scale Architectures
Investor Takeaway
Introduction
Nvidia still dominates AI training. That is not really the issue. The issue is inference economics. DeepSeek exposed that problem more than a year ago as hyperscalers increasingly focused on lowering deployment cost and reducing memory movement. The Cerebras IPO simply brought the discussion back into focus.
Training and inference are not the same thing. I like to think of AI as a professor-student relationship. The professor uses his vast knowledge to educate and teach his students. That’s training. Then the students graduate and go off and use all the training they learned in every aspect of their work. That’s inference.
Training still strongly favors Nvidia GPU clusters because training requires enormous compute scale, networking infrastructure, and High Bandwidth Memory (HBM) bandwidth. Nvidia dominates that environment through CUDA software integration, NVLink interconnect technology, InfiniBand networking, and the company’s enormous installed software ecosystem. Nvidia’s latest GPU architecture, Blackwell, simply extends that dominance further.
Inference introduces different problems.
Inference economics become very different once deployment scales globally. Latency, memory movement, power consumption, and deployment cost matter much more. The issue is no longer simply building larger AI models. The issue increasingly becomes deploying those models efficiently across massive global workloads.
That distinction matters. By the way, many of the details in this article came from my presentation to Merrill Lynch BOE Asian institutional investors last year, before Cerebras.
According to Chart 1, Nvidia is expected to retain overwhelming dominance in AI training workloads during 2026. Inference workloads already look far more diversified. Tensor Processing Unit (TPU) deployments continue expanding inside Google. Amazon continues pushing its Trainium accelerators internally through Amazon Web Services (AWS). Hyperscalers increasingly deploy Application-Specific Integrated Circuits (ASICs) for workloads where deployment economics matter more than maximum flexibility. Cerebras enters this discussion as another architecture attempting to optimize specifically around inference rather than generalized GPU scaling.

Chart 1: Estimated AI Accelerator Market Share by Workload (2026E)
This does not mean Nvidia suddenly loses dominance. Nvidia still controls the most important software ecosystem in artificial intelligence infrastructure. That remains enormously important because hyperscalers cannot simply replace years of CUDA software optimization overnight. Nvidia also continues dominating networking infrastructure surrounding AI clusters, another advantage that becomes increasingly important as models scale.
Today’s Nvidia earnings call will likely still focus heavily on Blackwell demand, hyperscaler capital expenditures, networking growth, and gross margin expansion. Nvidia remains in an extraordinarily strong position financially. Nothing currently suggests meaningful deterioration in near-term demand. Blackwell demand likely remains supply constrained.
But investors may increasingly listen for something else. The issue may no longer simply be whether hyperscalers continue spending aggressively on AI infrastructure. The issue increasingly becomes how hyperscalers optimize AI deployment economics as inference workloads scale globally. That discussion naturally leads toward ASICs, TPUs, memory movement, power efficiency, and inference optimization.
Inference Is Becoming a Different Market Than Training
According to Table 1, training and inference increasingly reward different kinds of chips. Nvidia GPUs still dominate training because training large AI models requires enormous computing power tied together through massive memory and networking systems. Inference is different. Inference focuses more on efficiently deploying those trained models at lower cost and lower power consumption once usage scales globally. That increasingly explains why hyperscalers continue buying Nvidia GPUs while simultaneously developing their own AI chips for portions of inference workloads.
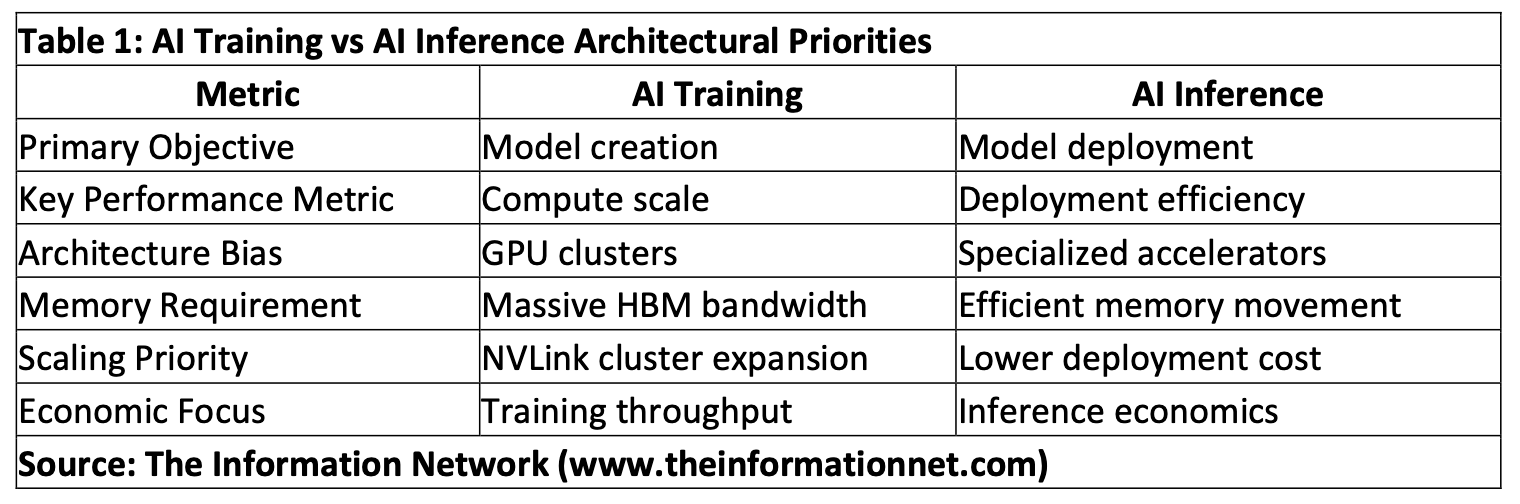
Training workloads still strongly favor Nvidia GPU clusters because training prioritizes massive computing power tied together through large memory and networking systems. Nvidia dominates that environment through CUDA software integration, NVLink interconnect technology, InfiniBand networking, and the company’s enormous installed software ecosystem. Nvidia’s latest GPU architecture, Blackwell, simply extends that dominance further. Inference workloads become more sensitive to memory movement, latency, deployment cost, and power consumption once AI deployment scales globally across billions of transactions. Traditional GPU architectures rely heavily on external High Bandwidth Memory (HBM), requiring enormous amounts of data movement between processors and memory systems. That architecture works extremely well for training large AI models where raw compute throughput matters most. Cerebras becomes important because its wafer-scale architecture attempts to reduce those memory-transfer bottlenecks by integrating large SRAM memory pools directly onto the processor itself.
Why Cerebras Matters Beyond Its IPO
According to Table 2, inference increasingly appears to be evolving toward multiple specialized architectures rather than one dominant compute model. Nvidia still dominates through CUDA, networking scale, and hyperscaler deployment experience. Cerebras, however, is attempting to optimize specifically around inference latency and memory movement through wafer-scale integration and large SRAM memory pools. TPU, Trainium, and Groq similarly reflect how hyperscalers increasingly prioritize inference economics rather than simply maximizing compute scale.